模型們還在進行狂熱的“諸神之戰”,嘗過鮮的用戶卻無法忽視大模型的短板。在交互過程中,用戶常常被它們一本正經的胡言亂語所打敗——對于部分問題,它們會輸出一些“看似非常有道理,實則完全不對”的內容,讓人啼笑皆非。
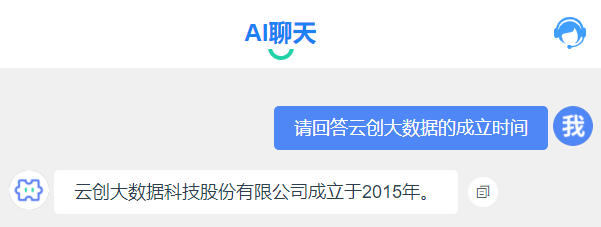
云創大數據成立于2011年,并不是2015年
之所以出現這種“AI幻覺”,是因為大模型的內容由推理而來,而在其自身訓練過程中也不可避免存在數據偏差。因此,當提問超出其訓練范圍,大模型可能會模糊回答,或者一本正經地胡謅。
娛樂一下沒有關系,但是對于數據準確性有著較高要求的用戶,這樣的通用性大模型可能會是負擔,進而導致大模型應用的普及度沒有想象的高(根據摩根士丹利發布的一項調查顯示,只有4%的人表示對于ChatGPT使用有依賴)。
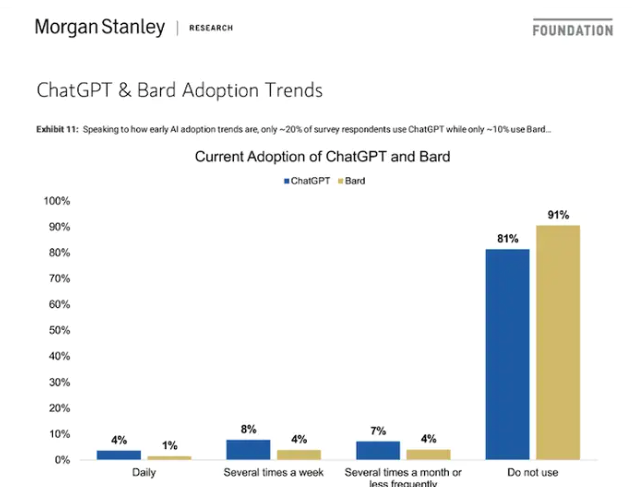
ChatGPT&Bard應用趨勢(圖片來源:摩根士丹利報告)
有沒有辦法改善大模型回答不準確的情況?當然有。既然回答不準確是因為缺少真正有用的知識參考,可以面向特定領域定制行業大模型,將可信來源的數據轉化成向量數據存儲起來,校準大模型推理輸出的結果,從而使大模型輸出的結果更加準確。
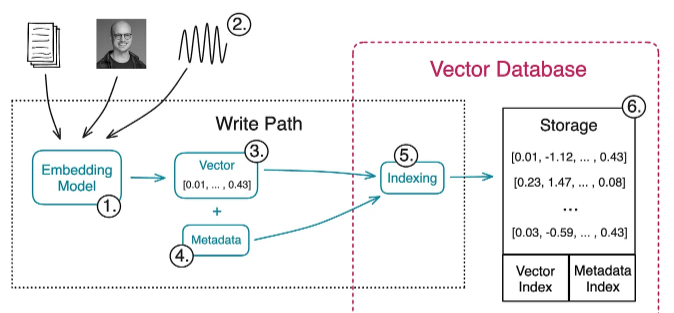
各種對象轉換為向量存儲在向量數據庫中(圖片來源:swirlai.com)
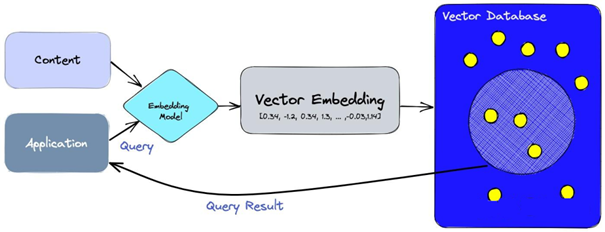
向量比對過程(圖片來源:Pinecone)
對于企業而言,可基于大模型和企業的個性化數據建立專屬知識庫(Knowledge Base)。可參照以下大模型業務流程,建立企業知識庫,以可信可靠的數據和知識,提高大模型輸出的準確率。
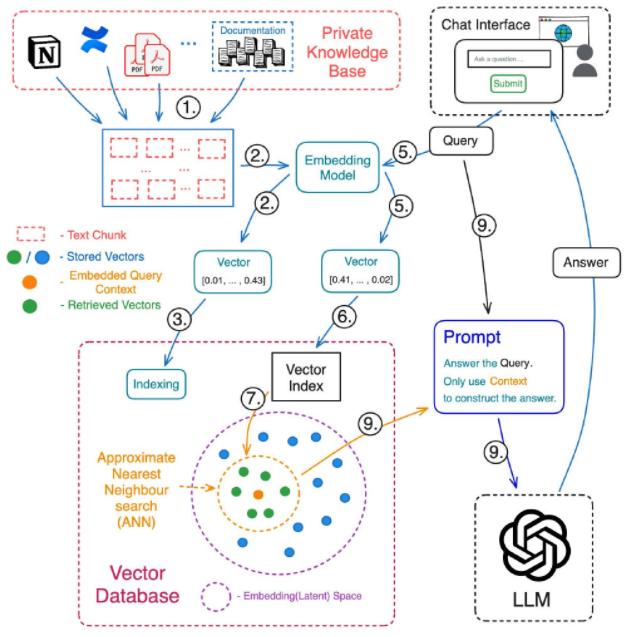
LLM大模型知識庫業務流程(圖片來源:swirlai.com)
首先,將企業的知識庫文本語料分割為多個塊,用嵌入(Embedding)模型將分割的文本塊轉換為一個個向量存儲在向量數據庫中,并建立向量和文本之間的對應關系,如上圖①-③所示。
此后,就可以提出問題。需要注意的是,問題也需要進行向量化,同時使用與知識庫語料向量化相同的嵌入模型,并且在向量數據庫中進行查詢,找到相似度高的向量,如⑤-⑦所示。
將返回的向量嵌入映射到對應的文本塊,并返回給大模型,利用大模型的語義理解能力,結合上下文生成問題答案,如⑧-⑨所示。
在建立企業知識庫后,同樣的問題再問大模型,它能給出準確的回答(建立知識庫的過程類似于下圖提供參考信息的過程)。
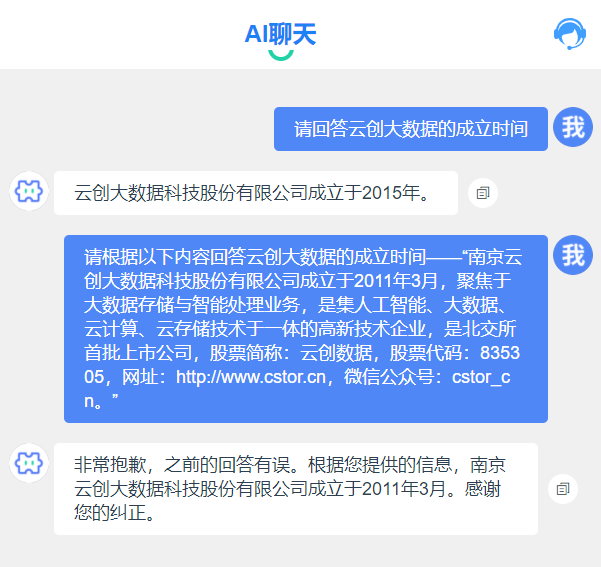
建立知識庫的過程類似于上圖提供參考信息的過程
實現私有化部署后,大模型“胡言亂語”的習慣開始逐漸被糾正,而且向量數據庫做的越大,它掌握的知識越多、越準確、越全面,就越有可能帶來爆炸式的大模型應用。
不過,如果只是依靠向量數據庫進行私有化部署,容量有限且速度比較慢,無法完全滿足企業通過大模型提質增效的潛在需求。
現在,cVector向量計算一體機通過發揮高性能硬件、向量加速算法和并行計算算法的合力,致力于滿足億級乃至百億千億向量規模的大模型推理應用向量計算需求。

cVector向量計算一體機
cVector向量計算一體機的使用方式與向量數據庫基本一致,支持批量、追加入庫,支持向量間歐式距離、余弦距離等向量計算,支持網頁、命令調用、Python庫等方法,但在向量的入庫和比對計算上具有驚人的性能。
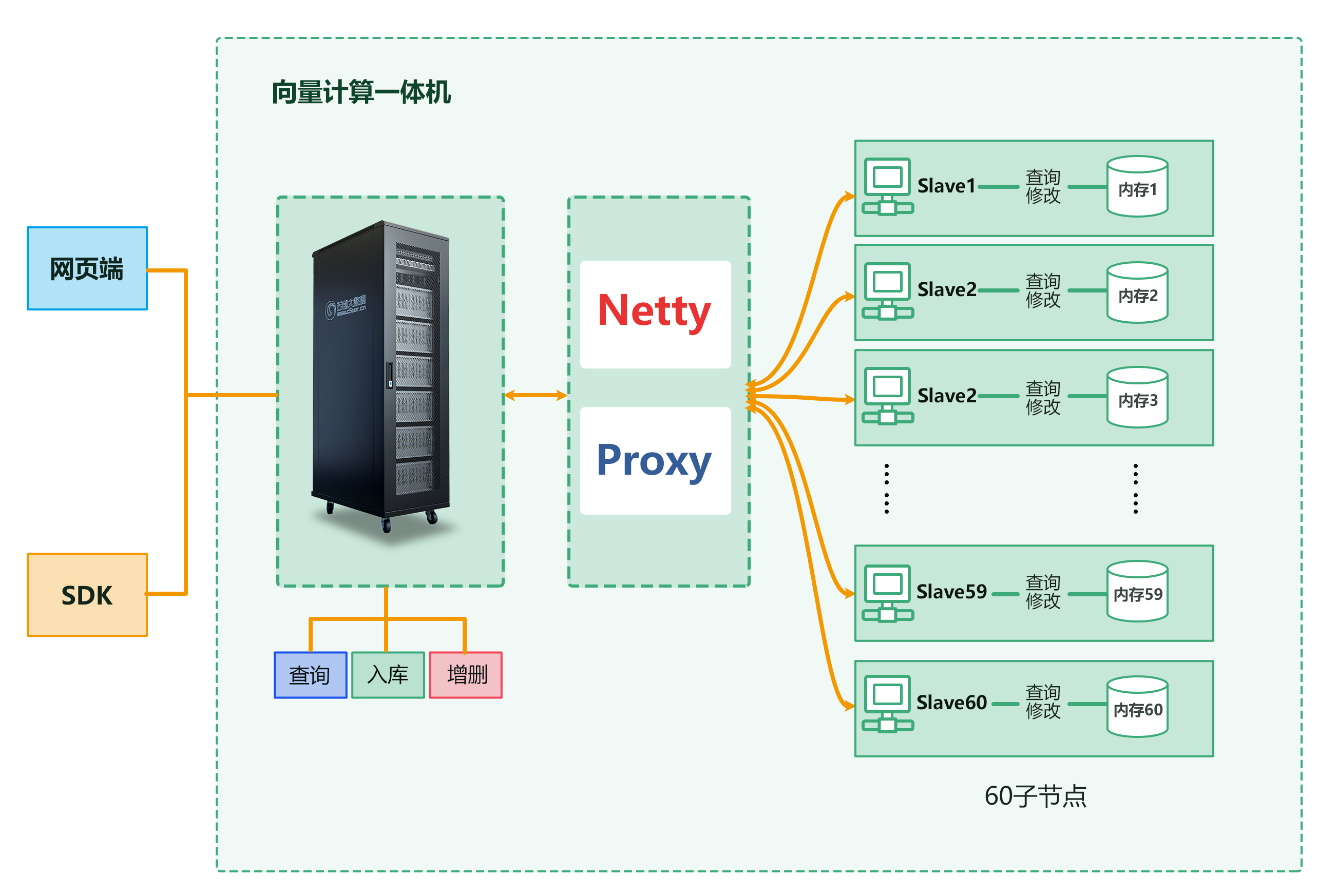
cVector向量計算一體機架構圖
近期, cVector向量計算一體機接受了工信部直屬的國家一級科研事業單位中國軟件評測中心的鑒定測試。中國軟件評測中心對比測試了cVector向量計算一體機與3款主流向量數據庫在入庫速度、查詢速度、準確性等維度的性能對比。
在入庫性能方面,同樣入庫3000萬條256 維向量數據,在向量數據庫中最快的是A,入庫速度是4851.97s,cVector向量計算一體機是1202.91s,入庫速度約是向量數據庫A的4倍,向量數據庫C的50倍,向量數據庫B的113倍;當入庫數據達到1億條時,向量數據庫A的入庫速度是17295.49s,cVector向量計算一體機是4484.55s,入庫速度約是前者的3.9倍。
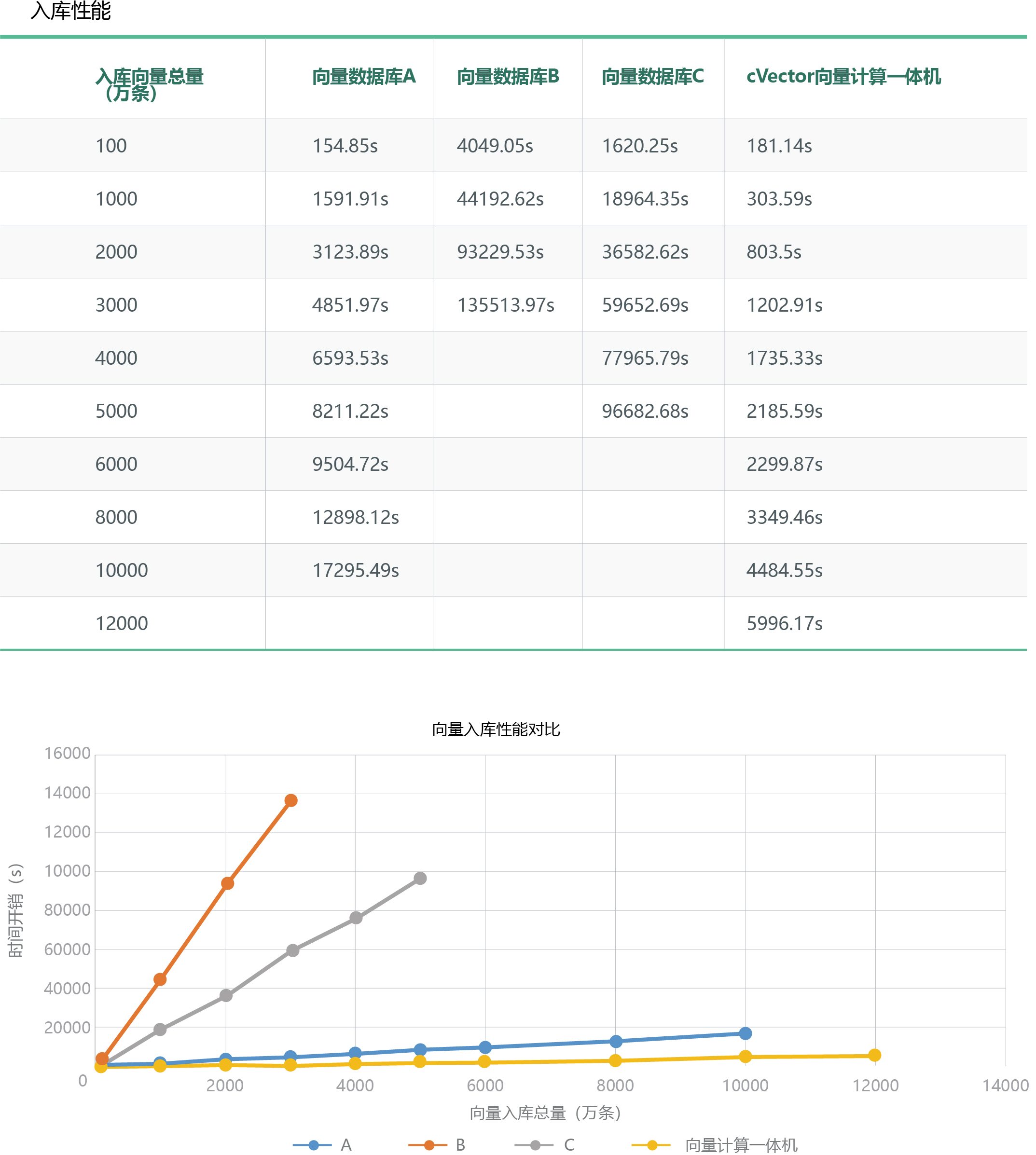
入庫性能比對
在查詢性能方面,同樣查詢1億條256 維向量數據,向量數據庫A的查詢速度是512.8s,cVector向量計算一體機是0.27s,查詢速度是前者的1899倍,而其他兩家測試向量數據庫由于數據量太大無法入庫比較。
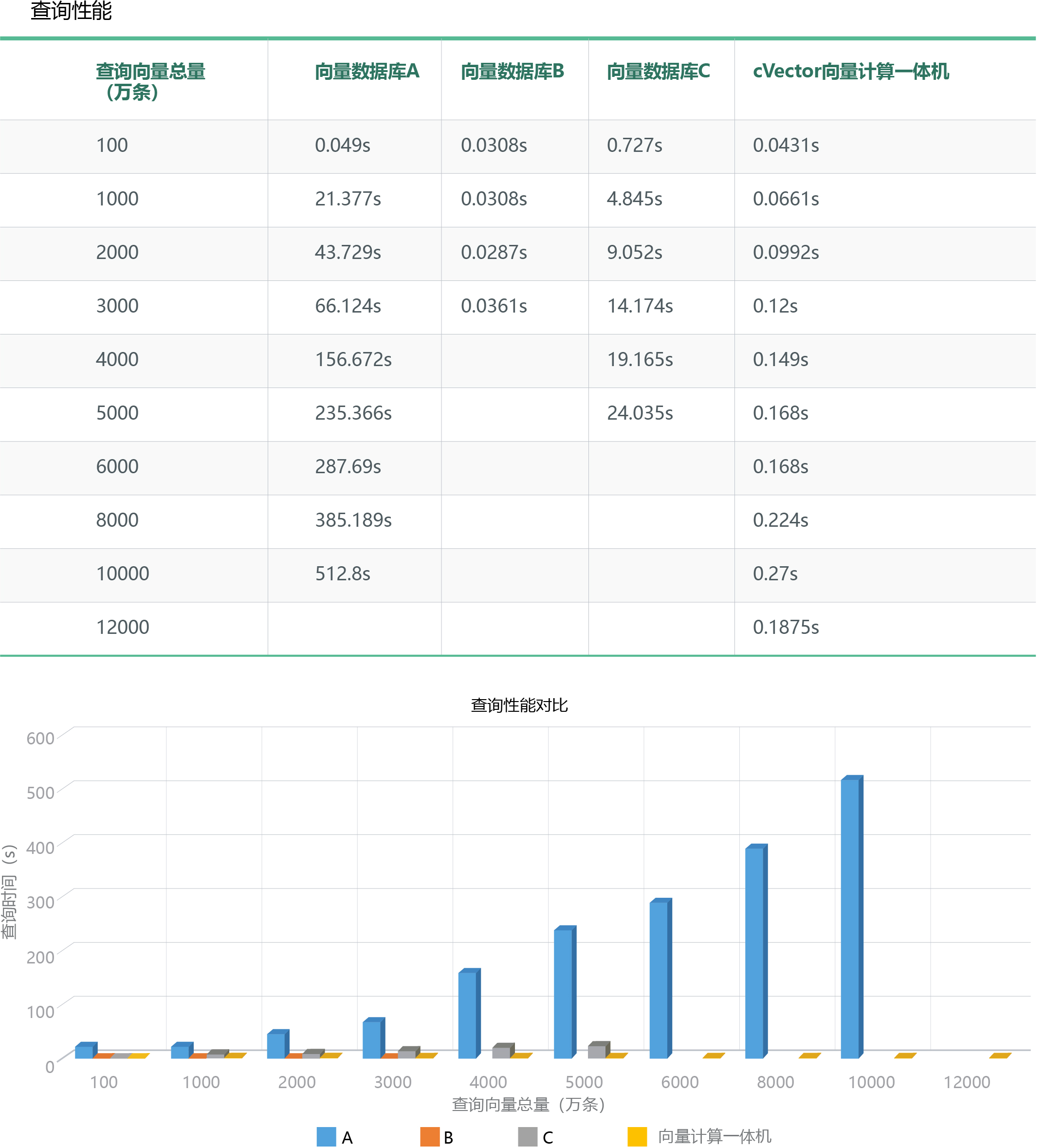
查詢性能對比
在準確性方面,cVector 向量計算一體機、向量數據庫A、向量數據庫B和向量數據庫C的數據準確度一致,通過了中國軟件評測中心(工業和信息化部軟件與集成電路促進中心)單項性能測試。
cVector向量計算一體機在億級乃至百億千億向量規模的的入庫和查詢等方面具有顯著的性能優勢,可幫助提高大模型推理的服務性能和服務質量,并能明顯降低其基礎設施建設成本,助力類ChatGPT等人工智能企業以更優的性價比解決算力不足的問題。
在具體應用方面,對于生成式AI相關企業,cVector向量計算一體機主要面向大模型推理應用,能夠在下述大模型推理環節發揮顯著作用:
①提高生成式AI的輸出準確性。由于大模型的輸出結果是根據概率推理而成,所以會出現“一本正經說胡話”的情形。可以將可信來源的數據轉化成向量數據存儲在向量計算一體機中,校準大模型推理輸出的結果,從而使大模型輸出的結果更加準確。
②提升大模型理解互聯網實時數據的能力。大模型基于歷史數據訓練而成,所以“只知道過去,不知道現在”。如果使用向量計算一體機存儲海量實時數據所轉化成的向量數據,可以幫助大模型理解掌握實時情況。
③提升大模型對用戶的服務質量。向量計算一體機可以允許用戶上傳更多的數據,讓大模型掌握用戶個性化的背景資料,更好地學習理解用戶請求,更好地結合用戶的實際情況回答問題。
④減輕大模型的訪問壓力。用戶所提的大部分問題都是相似的常見問題,向量計算一體機可以緩存大量熱點問題,不需要經過大模型推理即可返回結果,從而大幅減少算力成本。
⑤幫助生成式AI過濾敏感內容。怎么防止生成式AI說錯話一直是一個挑戰性問題,而向量計算一體機可以存放敏感內容所對應的向量數據,在用戶提出請求時加以判斷,盡可能防止AI對敏感問題做出不恰當的回應。
cVector向量計算一體機能夠廣泛應用于人工智能領域中生成式AI的推理應用場景,為各類生成式AI企業提供高性價比的產品和解決方案,大幅增加大模型平臺的競爭力,歡迎各大企事業單位試用。
目前國內某家龍頭大模型研發機構已經開始在測試cVector向量計算一體機,他們反映原來的向量數據庫的確是一個大瓶頸,如果不解決,會嚴重制約大模型的表現。
聯系方式:
單先生 13770311887(微信同號)
點擊“此處”了解更多



