4月28日,云創大數據正式發文公布了云創學習工場可以為高校提供高質量免費直播授課的通知。消息一經發出,受到各高校的積極反饋。目前為止,已有56所高校通過微信小程序報名,選擇了相關課程,分布在全國29個省、直轄市和自治區。
從5月25日開始,這些高校的學生將學習《大數據》課程和《大數據導論》課程,并將免費使用云創大數據開發的大數據實驗平臺(本科與高職兩大平臺,金融、電子商務、數學統計等多個版本,共有424個大數據實驗)進行實戰實驗,可以享受到直播授課+答疑解惑+實驗實戰等個性化的服務和指導。
開課時間在即,請還沒報名,有意向選擇云創學習工場高質量免費直播授課的高校抓緊時間通過下文中小程序報名!具體課程詳情和相關細節,可閱讀后文!
注:《大數據》課程適合作為本科高校大數據專業必修課程、非大數據專業選修課程。《大數據導論》課程適合作為高職高專院校大數據專業必修課程、非大數據專業選修課程。各高校也可以同時選擇以上兩門課程!
《大數據》選課小程序碼:

《大數據導論》選課小程序碼:

針對目前高校面臨的課程、師資、科研支撐、成果轉化等瓶頸,云創專業共建結對子計劃可為合作院校提供“共同制定人才培養計劃、建設教材體系、高質量免費培養師資、全套專業課高質量免費在線直播教學、設計實驗室建設方案、協助學生實習、協助學生高質量就業、共建教育部協同育人項目、聯合科研項目申報與研究、聯合發表高質量論文、聯合科研成果報獎、助力科研成果轉化”共12項免費服務,在教育領域反響十分強烈。
其中,高質量免費培養師資和全套專業課高質量免費在線直播教學作為重要的兩項服務,受到不同層次高校的廣泛好評。而全套專業課高質量免費在線直播教學采用“雙師模式”——直播間老師負責授課,現場助教老師負責輔導,可以大大解決大數據和人工智能師資緊缺問題,提升教學質量。
為了幫助高校大數據專業建設快速落地,培養創新人才,云創大數據將從本學期5月25日開始,推出《大數據》和《大數據導論》免費在線直播課,歡迎各高校選修。
《大數據》適合于本科高校大數據專業必修課程和非大數據專業選修課程,《大數據導論》適合于高職高專院校大數據專業必修課程和非大數據專業選修課程。同時,為了保障高校的教學實踐效果,云創大數據還將為選修以上兩門課程的高校免費提供大數據實驗平臺(本科與高職兩大平臺,金融、電子商務、數學統計等多個版本,共有424個大數據實驗),讓高校享受直播授課+答疑解惑+實驗實戰等個性化的服務和指導。
云創大數據還計劃從下學期9月份開始提供9門大數據和人工智能專業的專業直播課程,敬請期待!具體課程如下:
大數據(本科):《大數據》、《Python程序設計》、《云計算》
大數據(專科):《大數據導論》、《Python語言》、《云計算導論》
人工智能(本科):《人工智能導論》、《Python程序設計》、《人工智能數學基礎》
人工智能(專科):《人工智能概論》、《Python語言》、《云計算導論》
如有疑問,請咨詢宋倩:
聯系方式:
郵箱:songqian@cstor.cn
手機:13905177044

大數據(適合于本科高校)
一、課程性質、目的與要求
課程性質:本科高校大數據專業必修課程、非大數據專業選修課程。
課程目的:通過對大數據的相關知識介紹,使學生掌握大數據的概念和原理,熟悉大數據的理論與算法,了解大數據未來發展趨勢,能夠利用所學知識,進行大數據應用實現和算法設計,培養學生運用大數據技術解決大數據行業應用問題。
課程要求:本課程系統介紹了大數據的理論知識和實戰應用,包括大數據概念與應用、數據采集與預處理、數據挖掘算法與工具、R語言、深度學習以及大數據可視化等,并深度剖析了大數據在互聯網、商業和典型行業的應用。期望學生對大數據處理技術有比較深入的理解,能夠從具體問題或實例入手,利用所學的大數據知識在應用中實現數據分析和數據挖掘。
二、教學內容
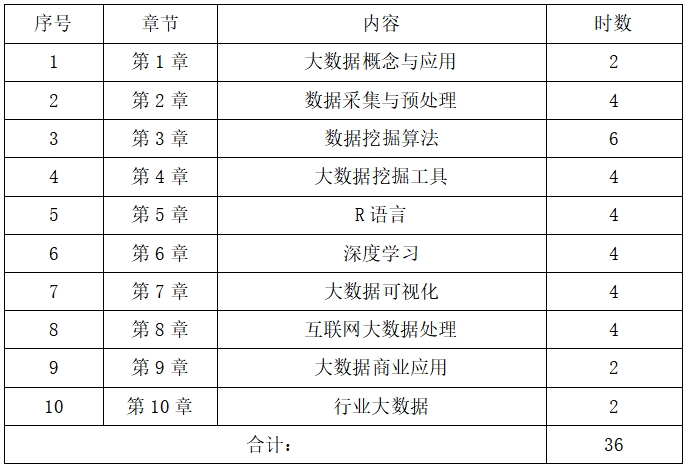
總學時:36學時
第1章 大數據概念與應用 2學時
基本要求:熟悉大數據的概念與意義、大數據的來源、大數據應用場景及大數據處理方法等內容。
重點:大數據的定義、研究內容與應用。
難點:無。
第2章 數據采集與預處理 4學時
基本要求:熟悉常用的大數據采集工具,特別是Apache Kafka數據采集使用方法;熟悉數據預處理原理和方法,包括數據清洗、數據集合、數據轉換;掌握數據倉庫概念與ETL工具Kettle的實際應用。
重點:Apache Kafka數據采集、數據清洗、數據倉庫與ETL工具。
難點:ETL工具Kettle的實際應用。
第3章 數據挖掘算法 6學時
基本要求:熟悉常用的數據挖掘算法,內容上從分類、聚類、關聯規則和預測模型等數據挖掘常用分析方法出發掌握相對應的算法,并能熟練進行數據挖掘算法的綜合應用。
重點:分類算法、聚類算法、關聯規則、時間序列預測。
難點:數據挖掘算法的綜合應用。
第4章 大數據挖掘工具 4學時
基本要求:熟練掌握機器學習系統Mahout和大數據挖掘工具Spark Mllib下的分類算法、聚類算法、協同過濾算法的使用,并對其他數據挖掘工具有所了解。
重點:Mahout安裝與使用、Spark Mllib工具的使用。
難點:Mahout和Spark Mllib工具的使用。
第5章 R語言 4學時
基本要求:了解R語言的發展歷程、功能和應用領域;熟悉R語言在數據挖掘中的應用;掌握R語言在分布式并行實時計算環境Spark中的應用SparkR。
重點:R語言基本功能、R語言在數據挖掘中的應用、SparkR主要機器學習算法。
難點:R語言與數據挖掘。
第6章 深度學習 4學時
基本要求:了解深度學習的發展過程和實際應用場景,并結合人腦的工作原理,理解深度學習的相關概念和工作機制,做到能夠熟練使用常用的深度學習軟件。
重點:人腦神經系統與深度學習、卷積神經網絡、深度置信網絡、循環(遞歸)神經網絡、TensorFlow和Caffe。
難點:人工神經網絡。
第7章 大數據可視化 4學時
基本要求:熟悉大數據可視化的基礎知識;掌握文本可視化、網絡可視化、時空數據可視化、多維數據可視化等常用的大數據可視化方法,可通過Excel、Processing、NodeXL和ECharts軟件實現數據的可視化。
重點:數據可視化流程、大數據可視化方法、大數據可視化軟件與工具。
難點:時空數據可視化、多維數據可視化。
第8章 互聯網大數據處理 4學時
基本要求:掌握互聯網信息抓取技術,能夠通過互聯網信息抓取、文本分詞、倒排索引與網頁排序這4個主要步驟實現互聯網大數據處理,并能夠熟練運用。
重點:Nutch爬蟲、文本分詞、倒排索引、網頁排序。
難點:倒排索引。
第9章 大數據商業應用 2學時
基本要求:熟悉用戶畫像和精準營銷的構建;熟悉廣告推薦系統的建設;熟悉互聯網金融的應用方法。
重點:用戶畫像構建流程、用戶標簽、廣告推薦、互聯網金融應用方向。
難點:信用評分算法、分類模型的性能評估。
第10章 行業大數據 2學時
基本要求:以地震大數據、交通大數據、環境大數據和警務大數據為例來熟悉行業大數據的應用,學會利用數據創造價值。
重點:理解數據和數據分析在業務活動中的具體表現。
難點:無。
三、課程安排
通過在線直播的方式進授課。授課時間為:2020年5月25日開課
具體課程安排如下:
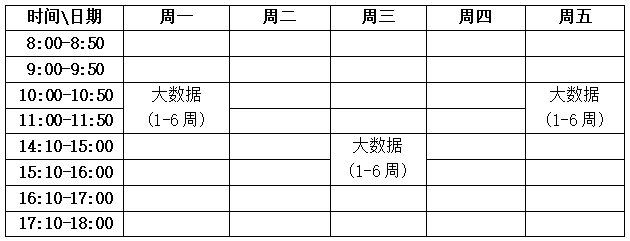
四、課時分配
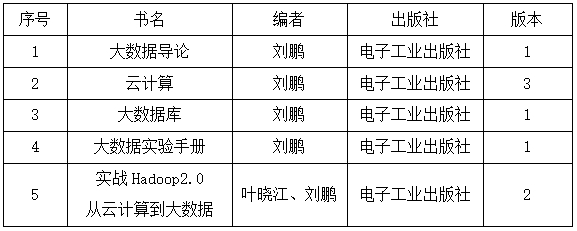
五、建議教材與教學參考書
一、課程性質、目的與要求
課程性質:高職高專院校大數據專業必修課程、非大數據專業選修課程。
課程目的:本課程力求加深學生在程序設計方法上的理解和把握,通過相關的事例讓學生對各知識點先了解,再理解,最后逐步掌握。整個過程融“教、學、練”于一體,加強學生實踐動手能力、獨立思考問題和解決問題的能力,達到正確靈活地利用操作系統各知識點來解決相關問題的目標,并為后續專業基礎課程、專業課程的學習奠定扎實的基礎。
課程要求:本課程在教學過程中,根據高職培養應用型人才的特點,以典型工作任務為主線、以各種資源管理為核心,以培養能力和提高興趣為目標,變應試為應用,重視在新形勢下的新方法、新規則和新思想的傳授。著重培養學生能靈活應用這些思想和方法的能力。課程教學中要遵循理論來自于實踐的原則,融“教、學、練”于一體,體現“在做中學,在學中做,學以致用”,以增強知識點的實踐性,激發學生的學習興趣。在實踐教學環節中則融入相關理論知識,突出理論來自于實踐和指導實踐的作用,使學生的知識應用根據學習的內容提升一個新的高度。
具體目標:
知識目標
?大數據基本概念和應用
?大數據的架構
?大數據的采集和預處理
?大數據的存儲
?大數據分析
?大數據可視化
?大數據的商業應用
技能目標
?大數據的基本概念和應用范圍
?理解大數據架構的相關概念
?理解大數據采集和預處理相關的概念,掌握數據采集相關技術的應用,了解大數據預處理相關技術
?理解大數據存儲相關概念,掌握大數據存儲相關技術
?了解大數據分析相關概念,了解大數據分析的相關技術
?理解數據可視化的相關概念,掌握大數據可視化的相關技術
?了解大數據的商業應用情況
二、教學內容
總學時:36學時
第1章 大數據基本概念和應用 2學時
基本要求:了解大數據的相關概念,了解大數據的來源、特征和意義、了解大數據的表現形態、了解大數據的各種應用場景。
重點:大數據的定義、大數據的市場應用。
難點:無。
第2章大數據的架構 4學時
基本要求:掌握大數據的分類,了解數據類型,了解大數據的解決方案、理解Hadoop的核心設計,了解Hadoop的平臺搭建。
第3章 大數據的采集和預處理 8學時
基本要求:熟悉常用的大數據采集工具,特別是Apache Kafka數據采集使用方法;熟悉數據預處理原理和方法,包括數據清洗、數據集合、數據轉換;掌握數據倉庫概念與ETL工具的實際應用。
重點:Apache Kafka數據采集、數據清洗、數據倉庫與ETL工具
重點:分類算法、聚類算法、關聯規則、時間序列預測。Apache Kafka數據采集、數據清洗、數據倉庫與ETL工具。ETL工具Kettle的實際應用
難點:數據挖掘算法的綜合應用。
第4章 大數據的存儲 6學時
基本要求:理解大數據存儲相關概念、理解數據倉庫的概念,了解數據倉庫的組成和構建方式、掌握大數據存儲相關技術的應用。
重點:云存儲系統的結構模型、分布式文件系統、數據庫。
第5章 大數據分析 8學時
基本要求:了解大數據分析相關概念,了解大數據分析的相關技術,通過上機項目實例進行練習。
重點:數據分析方法、數據挖掘算法。
第6章 大數據可視化 6學時
基本要求:熟悉大數據可視化的基礎知識;掌握文本可視化、網絡可視化、時空數據可視化、多維數據可視化等常用的大數據可視化方法,可通過Excel、Processing、NodeXL和ECharts軟件實現數據的可視化。
重點:數據可視化流程、大數據可視化方法、大數據可視化軟件與工具。
難點:時空數據可視化、多維數據可視化。
第7章 大數據的商業應用 2學時
基本要求:了解國外大數據應用經典案例以及以地震大數據、交通大數據、環境大數據和警務大數據為例來熟悉行業大數據的應用,學會利用數據創造價值。
重點:理解數據和數據分析在業務活動中的具體表現。
三、課程安排
通過在線直播的方式進授課。授課時間為:2020年5月25日開課
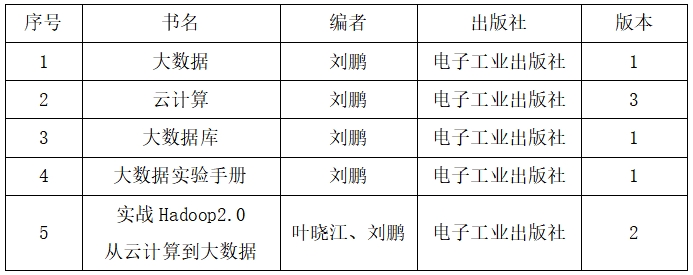
具體課程安排如下:
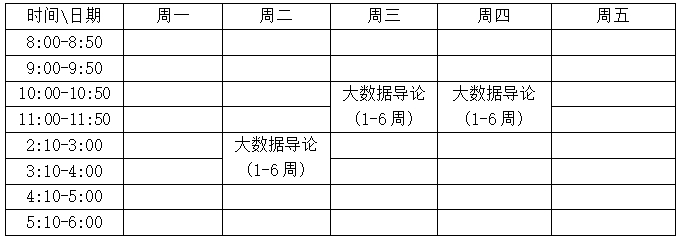
四、課時分配
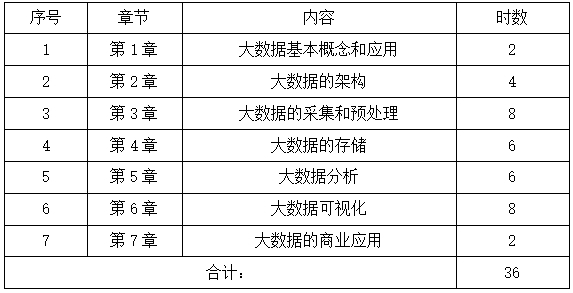
五、建議教材與教學參考書